
- A logistics company has directed all scans and incoming documents to a secured Google Drive account. The system automatically identifies the customer orders, invoices, airway bills, delivery instructions and contracts, extracts the data from these 12,000 daily documents and posts to company's legacy system without any manual intervention.
|

|
Automated Identification, Extraction and Integration of Documents (SaaS Architecture)
Contactous' Extractous is used to identify the incoming document, extract data from it, process it and then integrate it to a company's system. A use case is to automate this function within an office.
It is best explained by a simple flow diagram:
It is best explained by a simple flow diagram:
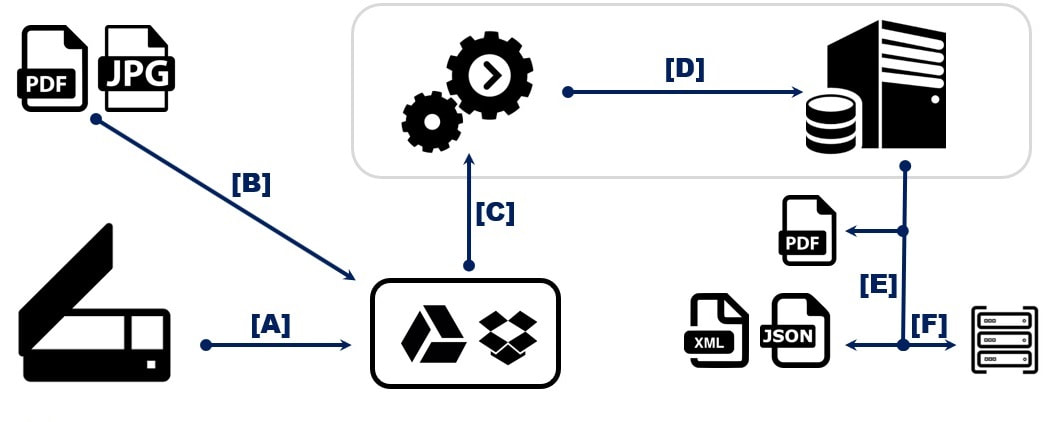
[A] - Majority of MFPs and Scanners can be programmed to send their output to a specific directory or cloud storage. This could be a company's secured FTP server or from a cloud provider like Google Drive or Dropbox. Scanned output in pdf or jpg format is sent to this location automatically.
[B] - PDF and image files from other sources can be directed to the same location as [A]. These could be uploaded from company's website, or output of an application, stripped attachment of specific emails, a separate storage location on the company's network or just manually uploaded. The company could be having different instances of such network storage and services from cloud storage providers.
[C] - A process on Contactous' cloud periodically scans the above storage location for new incoming documents. This scan can be set as per company's requirements. When it finds a new document, it identifies its type and intelligently extracts the rules that need to be applied to it and sends to Contactous' data extraction server which are also running on cloud.
[D] - Contactous server studies the document and applies the required rules to extract the data. Based on the setup, it generates the data values from each document and formats them in different files as needed by company's systems.
[E] - The output of [D] could be data files in CSV, XML or JSON format. Custom formats can be easily prepared as per company's requirements. If required the original document can be processed by adding metadata to it or extracted and adding OCR content from embedded images and saved to company's document management systems.
[F] - The data of [E] can be further formatted and integrated to company's systems. These could be through simple API to standard systems, sending files to watched folders or connecting to legacy systems through customized ETL scripts.
All the above steps take place automatically - A document gets scanned ([A]) or an email is received ([B]) and the entry is seen in DMS ([E]) or in CRM, ERP or SCM systems ([F]). No hardware or installation is required at company's site to achieve this as Contactous' environment ([C] and [D]) operates on cloud.
[B] - PDF and image files from other sources can be directed to the same location as [A]. These could be uploaded from company's website, or output of an application, stripped attachment of specific emails, a separate storage location on the company's network or just manually uploaded. The company could be having different instances of such network storage and services from cloud storage providers.
[C] - A process on Contactous' cloud periodically scans the above storage location for new incoming documents. This scan can be set as per company's requirements. When it finds a new document, it identifies its type and intelligently extracts the rules that need to be applied to it and sends to Contactous' data extraction server which are also running on cloud.
[D] - Contactous server studies the document and applies the required rules to extract the data. Based on the setup, it generates the data values from each document and formats them in different files as needed by company's systems.
[E] - The output of [D] could be data files in CSV, XML or JSON format. Custom formats can be easily prepared as per company's requirements. If required the original document can be processed by adding metadata to it or extracted and adding OCR content from embedded images and saved to company's document management systems.
[F] - The data of [E] can be further formatted and integrated to company's systems. These could be through simple API to standard systems, sending files to watched folders or connecting to legacy systems through customized ETL scripts.
All the above steps take place automatically - A document gets scanned ([A]) or an email is received ([B]) and the entry is seen in DMS ([E]) or in CRM, ERP or SCM systems ([F]). No hardware or installation is required at company's site to achieve this as Contactous' environment ([C] and [D]) operates on cloud.
Automated Document Parser (On-Premise Architecture)
The above configuration can be deployed on-premise. Here we take the core component of Extractous (minus the built-in document management system and integrated contact/user manager) and deploy it on-site.

[A] - This is the internal file server or local storage of organization. It can be the output directory of scanners or uploaded documents from websites.
[B] - On-premise Contactous server, constantly monitoring incoming documents in [A]. Contains extraction rules for each document type in [A].
It routinely pulls the document, intelligently selects the rules to apply and extracts data.
[C] - Data formatted and then downloaded or automatically transferred to secure file servers. PDF files sent to configured directories.
[D] - Data integrated to standard or legacy systems like SCM, ERP or CRM
[B] - On-premise Contactous server, constantly monitoring incoming documents in [A]. Contains extraction rules for each document type in [A].
It routinely pulls the document, intelligently selects the rules to apply and extracts data.
[C] - Data formatted and then downloaded or automatically transferred to secure file servers. PDF files sent to configured directories.
[D] - Data integrated to standard or legacy systems like SCM, ERP or CRM