
CRM Data Quality (CDQ)
CDQ cleans large contact databases by finding complex patterns of duplicate data, achieves single version of truth through its Entity Resolution algorithms and executes real-time de-duplication checks on applications within the enterprise. |
Main FeaturesCDQ enables a data dictionary to be defined using the field constructor option. Hundreds of fields can be defined about the contact data which can be strings, numeric, text or date types. This definition can be modified at any time. Data can be uploaded from Comma Separated Values (CSV) or text files. The upload feature automatically attempts to map the incoming data to the fields in the data dictionary. Fields can be re-mapped or skipped if needed. Dozens of encoding options are available during import, with UTF-8 selected by default. During the import process, checks are performed on the completeness of data. The data can be added to an existing dataset or by default a new one will be created after a successful upload. External data can also be imported by connecting to applications like Salesforce, Eloqua and Zoho CRM. Any system with an API access can be integrated to CDQ. Data from multiple datasets can be merged after a common factor between them has been discovered by CDQ. Using its de-duplication rules, CDQ forms a cluster of records with this common criteria. These records can then be collapsed into a single golden record. The data custodian can do this merging manually or instruct CDQ to perform it automatically.
The following example will make it clearer. CDQ has found 4 common records which have been collapsed into a single golden record within CRM by the data custodian. 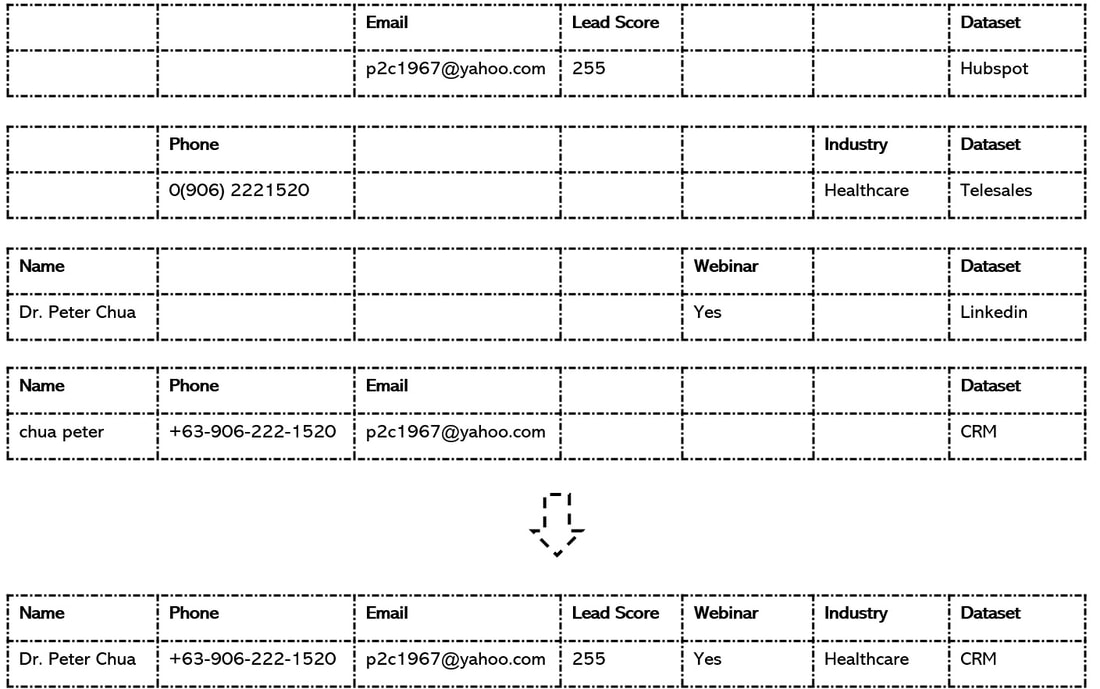
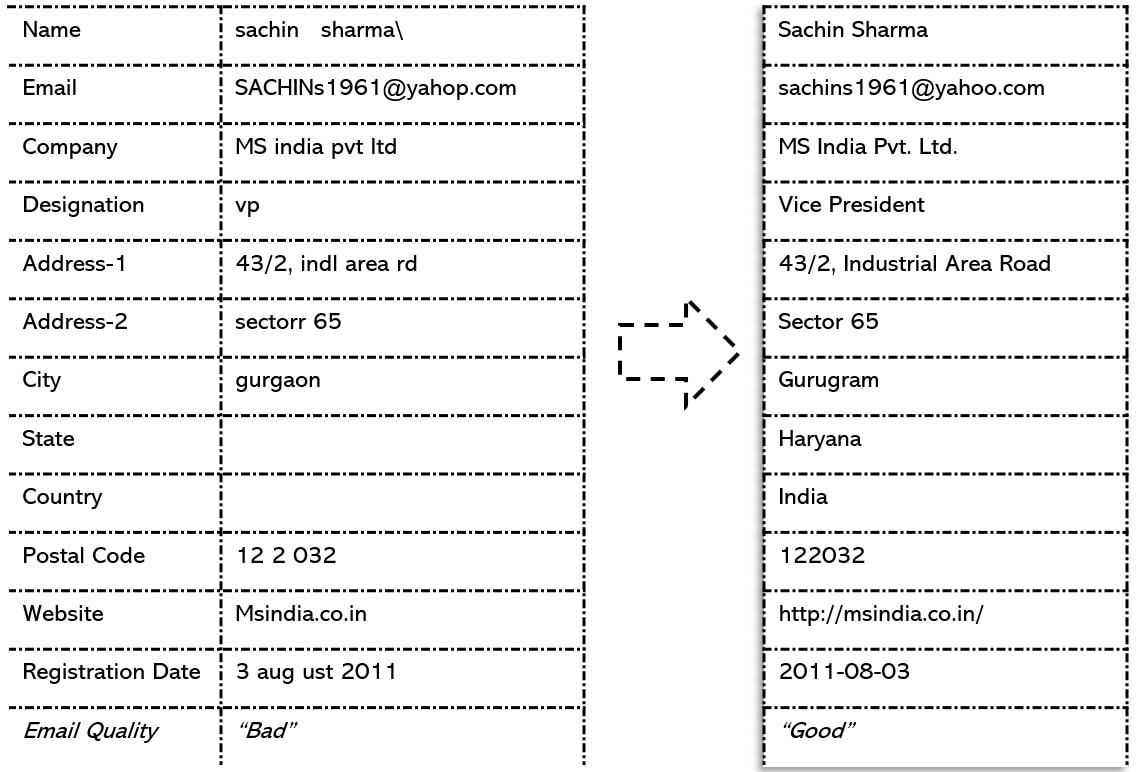
Using its pattern matching algorithms, CDQ can find common records across databases and multiple datasets. While the CSV and text files is usually directly uploaded into a dataset within CDQ , the data from external systems can be configured by either importing into CDQ or by storing the indexed keys of the records of that database. Storing the data within CDQ is optional. Essentially, it stores the key which it constructs after indexing the datasets. An external data system can be indexed by CDQ and that would be sufficient for it to compare that database with others or perform a real-time de-duplication on it. CDQ has dozens of functions to manually or automatically repair, standardize and enhance the data within its datasets. The strength of these functions is shown in the example below in which an incoming record on the left is passed through them, resulting in the final record on the right.
CDQ can find duplicates within seconds, across tens of millions of records. This de-duplication in real-time is being used by our customers from data entry to identification and in other innovative ways like explained in the example below:
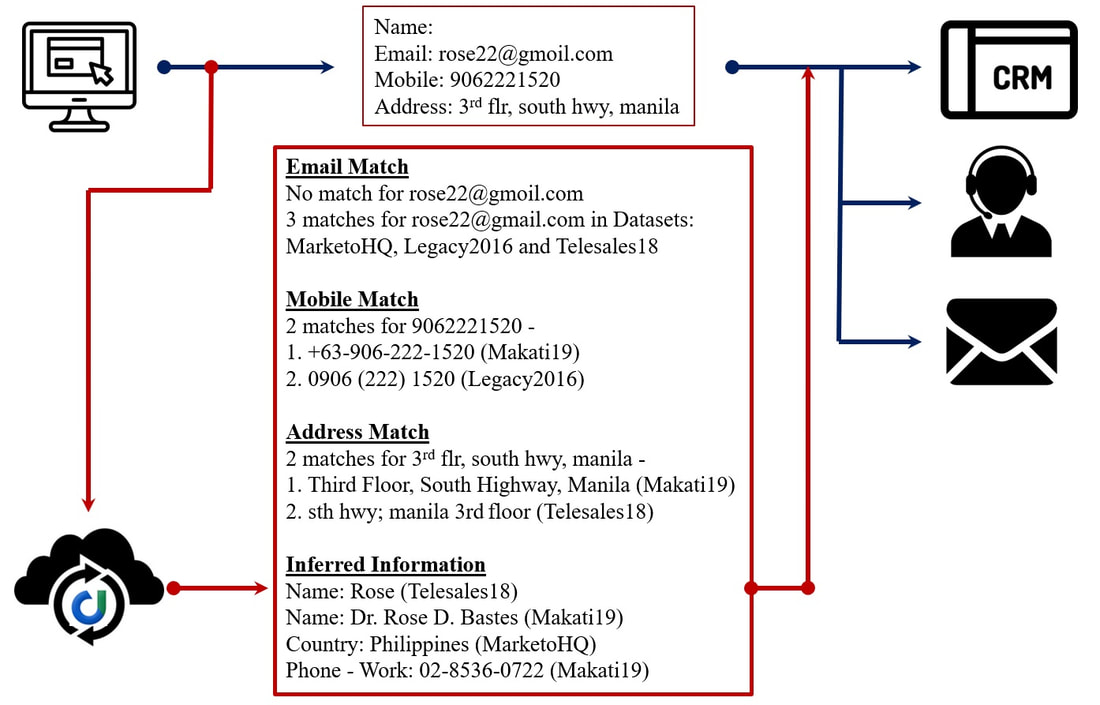
Before CDQ integration, the data is coming from a customer's web submission form and is being passed to CRM, telesales or lead-nurturing programs. In example above, CDQ is made to tap into this email (without integration) and it starts to perform the de-duplication for incoming records in real-time and sends that information to telesales. The actions (and their effectiveness) on original mail as compared to one sent by CDQ become very different. From merchant data records in banks to epidemiological data in hospitals and product descriptions in warranty management, large files with millions of records need to be quickly resolved to determine the right entity to be used through some agreed logic.
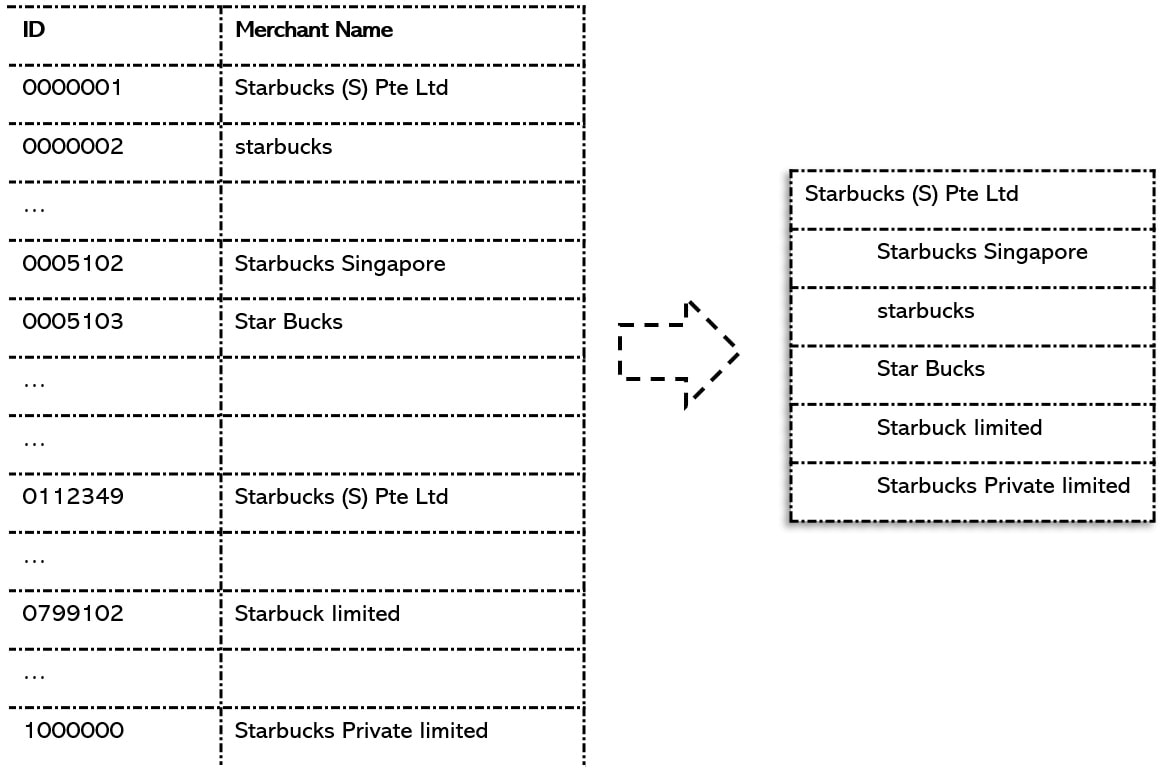
In the example above, a million records are received in text file by a financial institution comprising of merchant names. CDQ can take this entire data set and provide an entity resolution map within an hour about identity of the main entity and which other records in the incoming file correspond to that entity. Here, CDQ shows (based on configured rules) that Starbucks (S) Pte Ltd is the main entity and the 5 other names should correspond to this main record within the text file. With this resolution, the file can now be easily processed. Finding the duplicate records is part of the solution, merging them into a single version of truth is the next step. Once the cluster of duplicate records is found, it is important to determine the master record which will lead the merging process. CDQ has a rich set of configurable rules to determine which record would be the master record within a cluster. The user can always over-ride this suggestion. What happens to the records which get merged can be configured too. They can get deleted or moved to a special data set to be analyzed later. Then there are values that can get overwritten or ones which get appended. Lastly, the merging process itself can be automatic and CDQ can take responsibility of determining the master record and merge duplicate records of tens of thousands of clusters into their master record within an hour. Examples of Duplicate ClustersCDQ extracts clusters of duplicate records from single or multiple datasets, which could comprise of millions of records. Here are some examples. Majority of them are close to real cases of duplicate data found by the product during its usage. The real data has been changed for confidentiality, but the discovered pattern is intact.
Frequently Discussed Topics |